In my 11th grade biology class, with my lab partner, we dissected a fetal pig. I remember the aha moment when I realized what the diaphragm was. I had taken clarinet lessons for many years, and my teacher would always tell me to “breathe more with your belly, Read More
Today EBSCO Information Services (EBSCO) announced that PlumTM Analytics has become a wholly-owned subsidiary. We are excited about this big change because it will help us have the resources to realize the bright future we have for Plum Analytics, Read More
Since we started PlumX we understood that it was important to work with institutional and discipline-specific repositories, both as a source of research output as well as a target for providing value via PlumX metrics. PlumX imports records seamlessly from EPrints, Read More
We participated in a free Research Information webcast about Measuring Impact with Altmetrics on October 14th. Here is the description of the webcast: Altmetrics is a major buzz word at the moment and many publishers and others are experimenting with adding additional impact information to their papers. Read More
Last week, coinciding with our launch of our widget platform, we reached the milestone of moving PlumX out of beta. The earliest adopters of our research dashboards, the University of Pittsburgh and the Smithsonian, have made their PlumX directories public. Read More
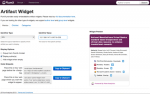
Over the past 6 months, we’ve been quietly improving upon our functionality on how to embed PlumX data about research impact into other applications and websites. This week, we added a feature that puts our widgets front and center in PlumX, Read More
I had the pleasure of attending the VIVO conference in St. Louis of the first time this year. I think one thing that is remarkable about the VIVO community is how much it truly is a welcoming group. From the weekly implementation calls to the face-to-face conference, Read More
We have recently added a feature where populating a PlumX researcher profile is as easy as creating a link to an existing VIVO profile. (VIVO is an open source semantic web application that is used in >30 countries and being implemented in more than 100 institutions.) So, Read More
For our customers, we have mechanisms in place for bulk importing data from existing systems to fuel: What is the hierarchy of data that you are interested in? What researchers are affiliated with the different groups? What artifacts are associated with particular researchers or groups? Read More