Don’t Judge a Book by Its Cover, or an Article by the Journal It Is Published In
We get questions from folks every now and then why we don’t use Journal Impact Factor to evaluate a particular article.
We often retort that “there are good articles in low JIF journals, and bad articles in high JIF journals.”
We can also discuss how retraction rates in high JIF journals are significantly higher than in low JIF journals.
Well – here is a study, A simple proposal for the publication of journal citation distributions, that just came out that shows how the same pattern appears across most journals: there are very few papers that get a lot of citations, and most of the papers get very few citations. This is consistent across journals, regardless of JIF.
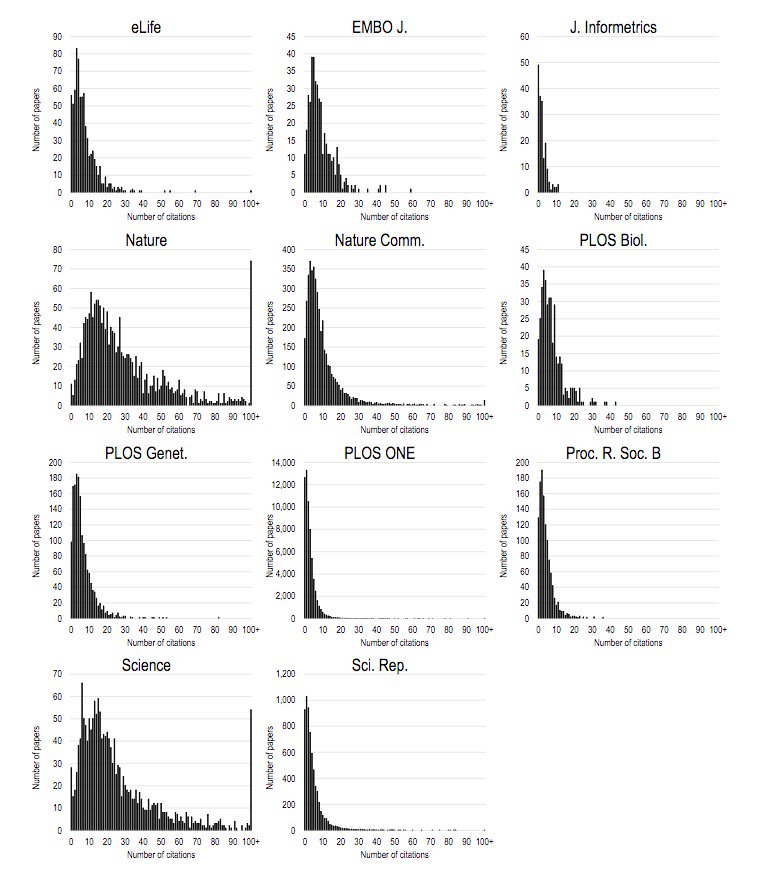
From the abstract:
Although the Journal Impact Factor (JIF) is widely acknowledged to be a poor indicator of the quality of individual papers, it is used routinely to evaluate research and researchers. Here, we present a simple method for generating the citation distributions that underlie JIFs. Application of this straightforward protocol reveals the full extent of the skew of distributions and variation in citations received by published papers that is characteristic of all scientific journals. Although there are differences among journals across the spectrum of JIFs, the citation distributions overlap extensively, demonstrating that the citation performance of individual papers cannot be inferred from the JIF. We propose that this methodology be adopted by all journals as a move to greater transparency, one that should help to refocus attention on individual pieces of work and counter the inappropriate usage of JIFs during the process of research assessment.
Key takeaway from the paper:
Although JIFs do vary from journal to journal, the most important observation as far as research assessment is concerned, and one brought to the fore by this type of analysis, is that there is extensive overlap in the distributions for different journals. Thus for all journals there are large numbers of papers with few citations and relatively few papers with many citations.
The authors’ conclusion:
The co-option of JIFs as a tool for assessing individual articles and their authors, a task for which they were never intended, is a deeply embedded problem within academia and one that has no easy solutions. We hope that by facilitating the generation and publication of journal citation distributions, the influence of the JIF in research assessment might be attenuated, and attention focused more readily onto the merits of individual papers – and onto the diverse other contributions that researchers make to research such as sharing data, code, and reagents (not to mention their broader contributions, such as peer review and mentoring students, to the mission of the academy).
Our summary:
To aid in evaluating and assessing research output, you need comprehensive metrics that can showcase the merits of the individual paper, not simply based on the journal it was published in.