Spotlight on Captures: Early indicators of citation counts
 More and more, policymakers are expecting scientists to demonstrate the value of their research to society. While peer review and bibliometrics have become accepted methods for assessing the impact research has on other research, there is currently no established framework that addresses the impact of research on the broader society. Because research is increasingly moving to the open web, even people outside of the scientific ecosystem are now able to participate in the discussion and dissemination of scientific discoveries. This opens the door for a new set of alternative indicators to measure societal impact: web-based metrics that track interactions with research outputs much earlier than traditional metrics could and also in the context of a broader audience.
More and more, policymakers are expecting scientists to demonstrate the value of their research to society. While peer review and bibliometrics have become accepted methods for assessing the impact research has on other research, there is currently no established framework that addresses the impact of research on the broader society. Because research is increasingly moving to the open web, even people outside of the scientific ecosystem are now able to participate in the discussion and dissemination of scientific discoveries. This opens the door for a new set of alternative indicators to measure societal impact: web-based metrics that track interactions with research outputs much earlier than traditional metrics could and also in the context of a broader audience.
The Researcher’s Process
Research involves many activities: from planning and ideation to literature review, experimentation, analysis, collaboration within and between academia and businesses, and ultimately, sharing research outputs and research outcomes with a larger audience (Fig. 1).
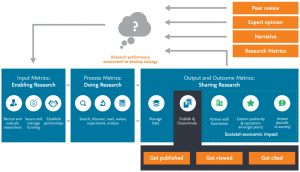
Fig. 1 Research workflow.[1]
Now, researchers can choose from a plethora of online tools to assist them on this path. Abstract and literature databases, social bookmarking sites, reference managers and online repositories for data are just a few that are noteworthy. Each of these tools offers unique opportunities to track the interaction of its users with the provided content, and therewith assess engagement with or usage of a specific research output. Metrics that track these engagements are therefore interesting complements to traditional metrics, as they help in telling a researcher’s story from new angles.
How data from citation management tools fit into that process
Determining impact based on the usage of items is not a new practice[2], and alternative metrics aren’t novel in the realm of applying usage data to assess scientific impact. The novelty of alternative metrics lies in the:
- New types of activities they can cover,
- Diversity of research outputs they can be applied to,
- Global scale at which their use is possible.
In the context of exploring how scholars discover and share academic material, there are a few sources that are particularly interesting.
Blog posts or Wikipedia references for instance are rich in content, indicating a strong interaction of an author with a research output, due to the amount of time it takes to investigate, reflect upon and produce such an item. However, they are rather rare occurrences and thus only cover a small fraction of published research outputs. On the other side there are sources that are ample, but poor in content. Many scholars use Twitter: tweets can be gathered, but the content is limited and often shows the promotion of an article.
Social bookmarking tools and reference managers occupy an interesting middle ground. Their broad adoption in the scholarly community and their reasonably good coverage of (especially) recent literature makes them a promising new source for evaluation purposes. Bookmarks to publications are a much clearer indication of a user’s interest in an output than tweets.[3] And, contrary to citation counts which often take several years to accrue, the readership of an article can be captured from the moment it appears online, often even before its official publication by tracking pre-print versions of articles, for instance in repositories such as arXiv, SSRN and RePEc.
Bookmarks can be leading indicators of citations
Two of the best known online reference managers are Mendeley and CiteULike. Both of these platforms allow users to save and organize information in their own online reference libraries and share this information with other users. Furthermore, tags or keywords can be assigned to an output, opening up the potential for crowd-sourcing annotations or social tagging. In addition to literature, users can add other products of scientific work to their library, such as data sets, illustrations, presentations, or even software. The reader count captures the number of users who save an item, thus expressing their interest in that particular output. This interest can have various motives: users might want to showcase their own outputs in their libraries, indicate what interests them, save items that they want to investigate in the future, or save items that they read and want to refer to in a future publication.
In the past few years, a lot of research has investigated the meaning of bookmarks in relation to traditional citation measures. In general, bookmarked articles seem to outperform non-bookmarked articles in terms of the amount of citation counts they receive[5]. A recent study showed that Mendeley readers accrue from the moment of an article’s appearance online, and then steadily build up[6]. Articles in journals with large publication delays may thus accumulate a significant readership way ahead of their official publication date.
For Mendeley, the correlation between reader and citation count is high, while for CiteULike medium correlations were observed.[5],[8] The different strength of the correlations for different bookmarking tools can have various reasons: while the lower coverage of articles in CiteULike could certainly cause a lower correlation, it could also reflect more societal impact or a different user base. High correlations on the other hand would then imply a more research-intensive nature of the user base. Bookmarks broaden the impact scope from authors to non-authors and include roles such as readers, fans, educators, problems solvers, etc. – traditional citation measures generally ignore these audiences.
Captures summarize readership metrics
Due to an ever expanding variety of online tools being made available, the pool of metrics for research evaluation is constantly growing. Organizing the myriad of metrics into categories makes them more meaningful for all different kinds of use cases in research assessment.[9] Classifications can serve as an infrastructure to govern and guide the understanding of metrics, and therewith help tell different stories and analyze “like with like”.
Within PlumX Metrics, reader counts and bookmarks fall into the category Captures, indicating that someone wants to come back to a piece of work. The category includes further metrics that are similar to bookmarks and reader counts, but in the context of different research outputs:
- Code forks in Github count how often repositories have been copied
- Favorites on Slideshare, Soundcloud and Youtube indicate how often an item has been marked as a favorite
- Subscribers and watchers on Vimeo, Youtube and Github indicate the number of people receiving updates for an item
- … and more
As the use of online reference managers becomes common practice and data sets grow over time, more investigation of their ability to challenge or complement traditional citation metrics will be possible. While data alone will never be enough to tell the whole story of research, quantitative inputs are an important piece in evaluating the impact of science. Qualitative input and human judgement are needed to complete the picture, but valuable insights can be gained from having a few pieces in place, even if there are gaps.
Sources:
[1] SciVal Usage Guidebook.
https://www.elsevier.com/__data/assets/pdf_file/0007/53494/ERI-Usage-Guidebook-1.01-March-2015.pdf
[2] Bollen, J., Van De Sompel, H., Smith, J. A. & Luce, R. Toward alternative metrics of journal impact: A comparison of download and citation data. Information Processing and Management 41, 1419–1440 (2005).
https://doi.org/10.1016/j.ipm.2005.03.024
[3] Gunn, W. Social Signals Reflect Academic Impact: What it means When a Scholar Adds a Paper to Mendeley. Information Standards Quarterly 25, 33 (2013).
https://doi.org/10.3789/isqv25no2.2013.06
[4] Bornmann, L. & Daniel, H. What do citation counts measure? A review of studies on citing behavior. Journal of Documentation 64, 45–80 (2008).
https://doi.org/10.1108/00220410810844150
[5] Sotudeh, H., Mazarei, Z. & Mirzabeigi, M. CiteULike bookmarks are correlated to citations at journal and author levels in library and information science. Scientometrics 105, 2237–2248 (2015).
https://doi.org/10.1007/s11192-015-1745-9
[6] Maflahi, N., Thelwall, M. How quickly do publications get read? The evolution of Mendeley reader counts for new articles. Journal of the Association for Information Science and Technology (2017). http://hdl.handle.net/2436/620522
[7] Bornmann, L. Alternative metrics in scientometrics: A meta-analysis of research into three altmetrics. Scientometrics 103, 1123–1144 (2015).
https://doi.org/10.1007/s11192-015-1565-y
[8] Li, X., Thelwall, M. & Giustini, D. Validating online reference managers for scholarly impact measurement. Scientometrics 91, 461–471 (2012).
https://doi.org/10.1007/s11192-011-0580-x
[9] Lin, J. & Fenner, M. Altmetrics in Evolution: Defining and Redefining the Ontology of Article-Level Metrics. Information Standards Quarterly 25, 20 (2013).
https://doi.org/10.3789/isqv25no2.2013.04